






Java岗大厂面试百日冲刺【Day26】—— Spring框架3
编辑
Java岗大厂面试百日冲刺【Day26】—— Spring框架3
本文已获得原作者 _陈哈哈 授权并经过重新整理规划后发布。
本栏目Java开发岗高频面试题主要出自以下各技术栈:Java基础知识、集合容器、并发编程、JVM、Spring全家桶、MyBatis等ORMapping框架、MySQL数据库、Redis缓存、RabbitMQ消息队列、Linux操作技巧等。
面试题1:Bean 的加载过程是怎样的?
我们知道, Spring 的工作流主要包括以下两个环节:
- 解析,读 xml 配置,扫描类文件,从配置或者注解中获取 Bean 的定义信息,注册一些扩展功能。
- 加载,通过解析完的定义信息获取 Bean 实例。
下面是跟踪了 getBean的调用链创建的流程图,为了能够很好地理解 Bean 加载流程,省略一些异常、日志和分支处理和一些特殊条件的判断。
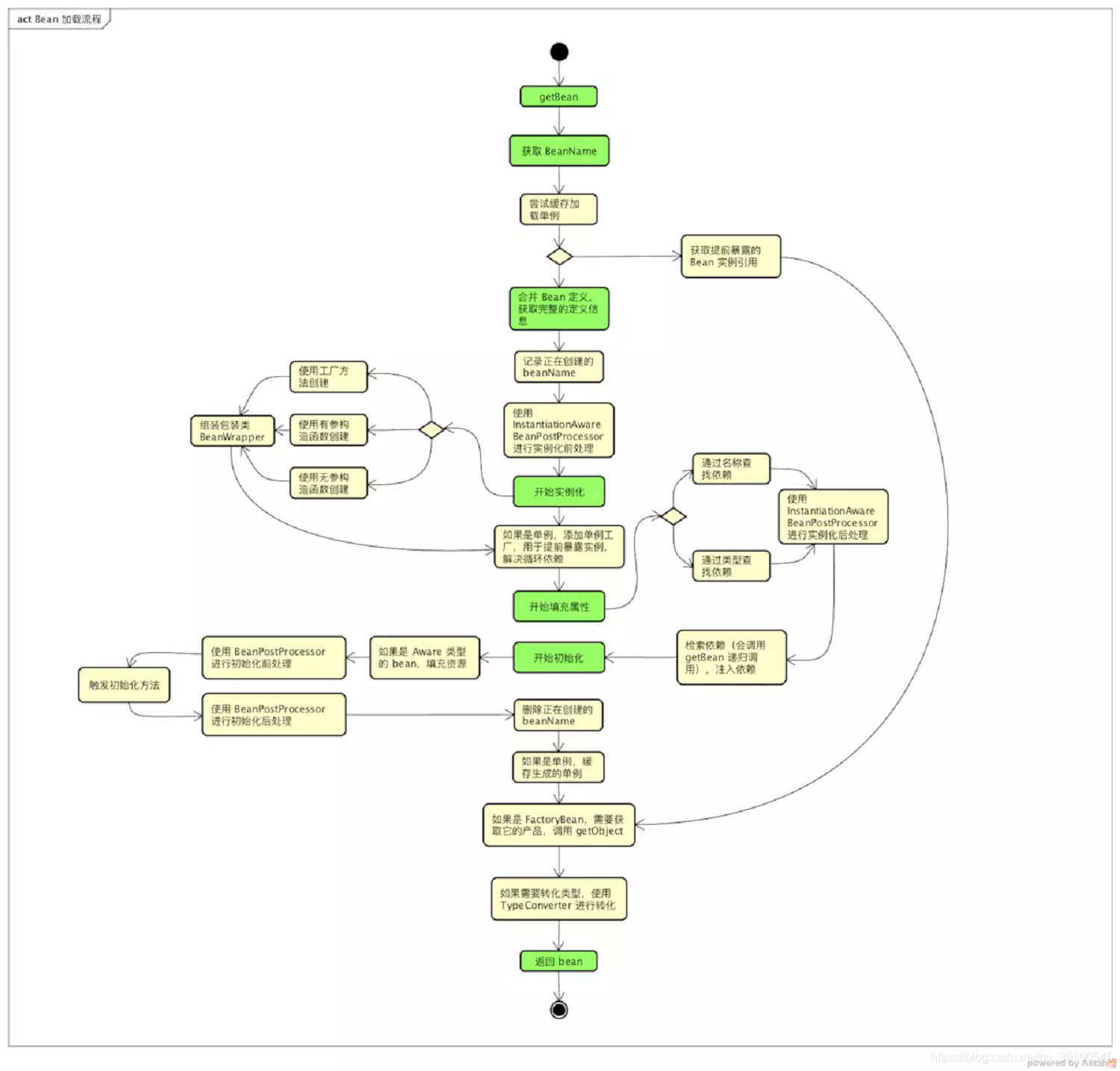
从上面的流程图中,可以看到一个 Bean 加载主要会经历这么几个阶段(标绿内容):
- 获取 BeanName,对传入的 name 进行解析,转化为可以从 Map 中获取到 BeanDefinition 的 bean name。
- 合并 Bean 定义,对父类的定义进行合并和覆盖,如果父类还有父类,会进行递归合并,以获取完整的 Bean 定义信息。
- 实例化,使用构造或者工厂方法创建 Bean 实例。
- 属性填充,寻找并且注入依赖,依赖的 Bean 还会递归调用 getBean 方法获取。
- 初始化,调用自定义的初始化方法。
- 获取最终的 Bean,如果是 FactoryBean 需要调用 getObject 方法,如果需要类型转换调用 TypeConverter 进行转化。
以上便是Spring对bean解析注册的全过程,总结一下大致步骤:
- 加载XML文件,封装成Resource对象;
- 调用Reader对象方法读取XML文件内容,并将相关属性放到BeanDefinition实例;
- 将BeanDefinition对象放到BeanFactory对象,用于调用;
追问1:什么是循环依赖?
举个例子,这里有三个类 A、B、C,然后 A 关联 B,B 关联 C,C 又关联 A,这就形成了一个循环依赖。如果是方法调用是不算循环依赖的,循环依赖必须要持有引用。
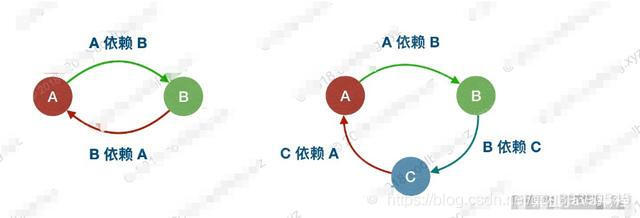
循环依赖发生的场景:
- 构造器循环依赖:依赖的对象是通过构造器传入的,发生在实例化 Bean 的时候。
- 设值循环依赖:依赖的对象是通过 setter 方法传入的,对象已经实例化,发生属性填充和依赖注入的时候。
如果是构造器循环依赖,本质上是无法解决的。比如我们准调用 A 的构造器,发现依赖 B,于是去调用 B 的构造器进行实例化,发现又依赖 C,于是调用 C 的构造器去初始化,结果依赖 A,整个形成一个死结,导致 A 无法创建。
如果是设值循环依赖,Spring 框架只支持单例下的设值循环依赖。Spring 通过对还在创建过程中的单例,缓存并提前暴露该单例,使得其他实例可以引用该依赖。
追问2:循环依赖得解决思路是什么样的?
Spring解决循环依赖,主要的思路就是依据三级缓存(解链)。
在实例化A时调用doGetBean,发现A依赖的B的实例,此时调用doGetBean去实例B,实例化的B的时候发现又依赖A,如果不解决这个循环依赖的话此时的doGetBean将会无限循环下去,导致内存溢出,程序奔溃。
如果Spring引用一个早期对象,并且把这个"早期引用"并将其注入到容器中,让B先完成实例化,此时A就获取B的引用,完成实例化。
- 一级缓存:singletonObjects,存放完全实例化属性赋值完成的Bean,直接可以使用
- 二级缓存:earlySingletonObjects,存放早期Bean的引用,尚未属性装配的Bean
- 三级缓存:singletonFactories,三级缓存,存放实例化完成的Bean工厂
面试题2:@Resource和@Autowired有什么区别?
@Autowired根据类型注入@Resource默认根据名字注入,其次按照类型搜索@Autowired@Qualifie("userService") 两个结合起来可以根据名字和类型注入,等同于@Resource
1.@Autowired与@Resource都可以用来装配bean. 都可以写在字段上,或写在setter方法上。
2.@Autowired默认按类型装配(byType),默认情况下必须要求依赖对象必须存在,如果要允许null值,可以设置它的required属性为false,如:@Autowired(required=false) ,如果我们想使用名称装配可以结合@Qualifier注解进行使用(@Autowired () @Qualifier ( "xxx" )功能同@Resource),如下:
@Autowired
@Qualifier ( "userDao" )
private UserDao userDao;
3.@Resource默认按照名称进行装配(byName),名称可以通过name属性进行指定,如果没有指定name属性,当注解写在字段上时,默认取字段名进行安装名称查找,如果注解写在setter方法上默认取属性名进行装配。当找不到与名称匹配的bean时才按照类型进行装配。如果name属性一旦指定,就只会按照名称进行装配。
@Resource (name= "baseDao" )
private BaseDao baseDao;
总结如下:
- @Autowired默认按byType自动装配,而@Resource默认byName自动装配。
- @Autowired只包含一个参数:required,表示是否开启自动注入,默认是true。而@Resource包含七个参数,其中最重要的两个参数是:name 和 type。
- @Autowired如果要使用byName,需要使用@Qualifier一起配合。而@Resource如果指定了name,则用byName自动装配,如果指定了type,则用byType自动装配。
- @Autowired能够用在:
构造器、方法、参数、成员变量和注解上,而@Resource能用在:类、成员变量和方法上。 - @Autowired是spring定义的注解,而@Resource是JSR-250定义的注解。
面试题3:Spring 的事务传播行为有哪些,都有什么作用?
简单来讲,就是当系统中存在两个事务方法时(我们暂称为方法A和方法B),如果方法B在方法A中被调用,那么将采用什么样的事务形式,就叫做事务的传播特性
比如,A方法调用了B方法(B方法必须使用事务注解),那么B事务可以是一个在A中嵌套的事务,或者B事务不使用事务,又或是使用与A事务相同的事务,这些均可以通过指定事务传播特性来实现。
| 传播行为 | 意义 |
|---|---|
| propagation.REQUIRED | 表示当前方法必须运行在事务中。如果当前事务存在,方法将会在该事务中运行。否则会启动一个新的事务 |
| propagation.SUPPORTS | 表示当前方法不需要事务上下文,但是如果存在当前事务的话,那么该方法会在这个事务中运行 |
| propagation.MANDATORY | 表示该方法必须在事务中运行,如果当前事务不存在,则会抛出一个异常 |
| propagation.REQUIRED_NEW | 表示当前方法必须运行在它自己的事务中。一个新的事务将被启动。如果存在当前事务,在该方法执行期间,当前事务会被挂起。如果使用JTATransactionManager的话,则需要访问TransactionManager |
| propagation.NOT_SUPPORTED | 表示该方法不应该运行在事务中。如果存在当前事务,在该方法运行期间,当前事务将被挂起。如果使用JTATransactionManager的话,则需要访问TransactionManager |
| propagation.NEVER | 表示当前方法不应该运行在事务上下文中。如果当前正有一个事务在运行,则会抛出异常 |
| propagation.NESTED | 表示如果当前已经存在一个事务,那么该方法将会在嵌套事务中运行。嵌套的事务可以独立于当前事务进行单独地提交或回滚。如果当前事务不存在,那么其行为与propagation.REQUIRED一样。注意各厂商对这种传播行为的支持是有所差异的。可以参考资源管理器的文档来确认它们是否支持嵌套事务 |
- 0
- 0
-
赞助
 微信赞赏
微信赞赏
 支付宝赞赏
支付宝赞赏
-
分享