
Java岗大厂面试百日冲刺【Day31】—— 消息队列1
本文已获得原作者 _陈哈哈 授权并经过重新整理规划后发布。
本栏目Java开发岗高频面试题主要出自以下各技术栈:Java基础知识、集合容器、并发编程、JVM、Spring全家桶、MyBatis等ORMapping框架、MySQL数据库、Redis缓存、RabbitMQ消息队列、Linux操作技巧等。
我们面试中常会被问到消息队列相关问题,但一般没有过于深入原理的,因为进了公司后大多时候队列都有专门的中间机组或人专门处理,基本轮不到咱们的~因此面试官主要还是想看你对队列这块儿的理解程度 以及 是否真会玩儿这个,就完了,因此不建议花费大量时间去深入研究原理。。有空多看看JVM和并发不香么。 个人理解,面试主要考察MQ的点大概包括:你丫之前系统为啥要用消息队列?是咋用的?你会玩儿么,还是用别人玩儿剩下的?为啥选择了这个MQ?常见的问题都知道咋整不?出问题你习惯背锅还是甩锅?。。。🙂🙂🙂
面试题1:说说你对消息队列的理解,消息队列为了解决什么问题?
我们公司业务系统一开始体量较小,很多组件都是单机版就足够,后来随着用户量逐渐扩大,我们程序也采用了微服务的设计思想,把很多服务进行了拆分,但后来在一些秒杀抢票活动或高频业务中,服务依旧扛不住大量QPS,因此我们引入了消息队列来优化该类问题。
消息队列应用的场景大致分为三类:解耦、异步、削峰。
解耦
消息队列类似设计模式中的观察者模式(Observer)或发布-订阅模式(Pub-Sub)。生产者生成和发送消息到消息队列,消费者从消息队列中取走消息进行处理,称为消费,使用消息队列将“生产者”和“消费者”之间的操作关联解耦,易于扩展。
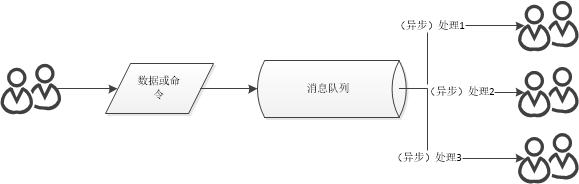
比如系统A为支付系统,一开始用户支付完调用日志记录系统B记录就完了,后来内容越来越多,支付完成要调用加积分系统C、短信通知系统D、优惠券系统E等
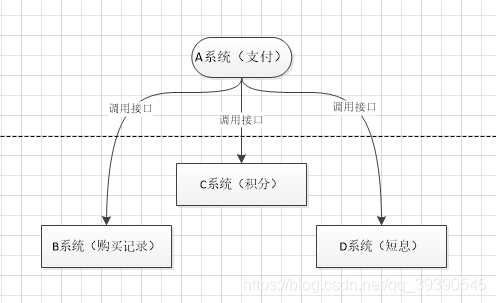
这个场景中,A 系统跟其它各种乱七八糟的系统严重耦合,A 系统产生一条支付成功的数据,很多系统接口都需要 A 系统调用把支付成功的数据发送过去。A 系统程序员要时刻考虑这些问题:
- 其他系统如果挂了该咋办?是不是直接程序抛异常了?
- 一天到晚加业务,每次都重新部署?领导是不是狗?
那如果引入 MQ,A 系统产生一条数据,发送到 MQ 里面去,每个子系统加上对消息队列中支付成功消息的订阅,持续监听就可以了,哪个系统需要数据自己去 MQ 里面消费。如果新系统需要数据,直接从 MQ 里消费即可;如果某个系统不需要这条数据了,就取消对 MQ 消息的消费即可。
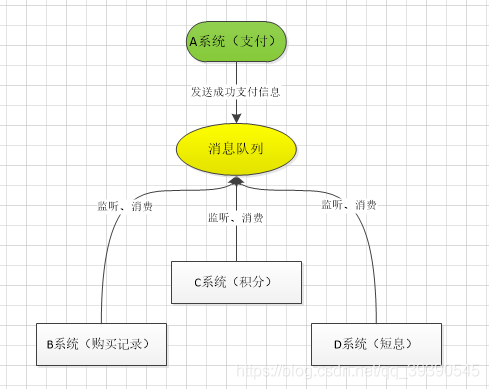
这样下来,A系统压根儿不需要去考虑要给谁发送数据,不需要维护这个代码,也不需要考虑人家是否调用成功、失败超时等情况,我只负责把支付成功的信息放到MQ里就行了,至于能否正常加积分、能否正常短信通知,管我鸟事!可见,通过一个 MQ,Pub/Sub 发布订阅消息这么一个模型,A 系统就跟其它系统彻底解耦了。
开玩笑的,当然不能这样做,这里其实涉及到MQ在分布式事务中数据一致性的问题。
数据一致性
这个其实是分布式服务本身就存在的一个问题,不仅仅是消息队列的问题,但是放在这里说是因为用了消息队列这个问题会更明显。
就像咱们上面说的,你支付成功的服务自己保证自己的逻辑成功处理了,你成功发了消息,但是短信系统,积分系统等等这么多系统,他们成功还是失败你就不管了?当然不行,这样坑队友的行为,狄大人都帮不了你~
怎么办?那就把所有的服务都放到一个事务里,所有都成功成功才能算这一次下单是成功的,要成功一起成功,要失败一起失败。
异步
A 系统接收一个请求,需要在自己本地写库,还需要在 BCD 三个系统写库,自己本地写库要 3ms,BCD 三个系统分别写库要 300ms、400ms、200ms。最终请求总延时是 3 + 300 + 400 + 200 = 903ms,接近 1秒,用户感觉搞个毛线?慢的一批。
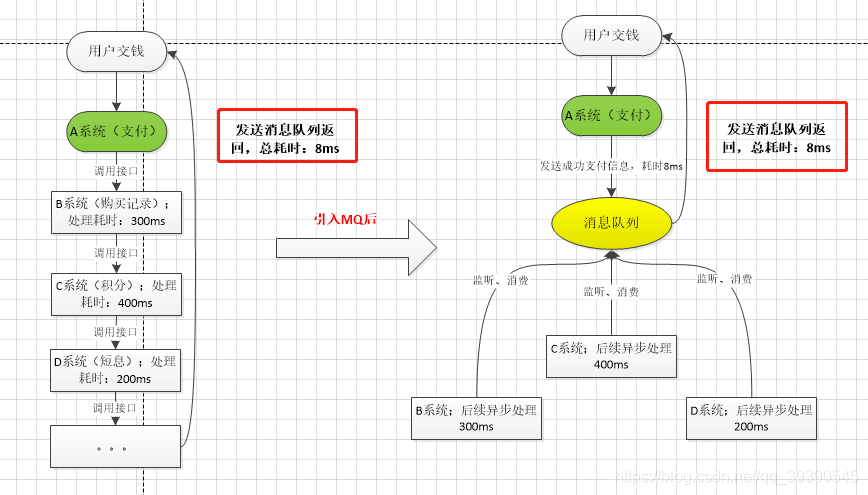
一般互联网类的企业,对于用户直接的操作,一般要求是每个请求都必须在 200 ms 以内完成,对用户几乎是无感知的,如果1秒足以说明该系统不可用,垃圾系统。
如果这里使用了消息队列,那么 A 系统连续发送 3 条消息到 MQ 队列中,假如耗时 5ms,A 系统从接受一个请求到返回响应给用户,总时长是 3 + 5 = 8ms,对于用户而言,其实感觉上就是点个按钮,8ms 以后就直接返回了,体验感很好
削峰
比如我们系统有代售抢票业务,平时每天QPS也就50左右,A 系统风平浪静。结果每次一到春运抢票,每秒并发请求数量突然会暴增到10000以上。但是系统是直接基于 MySQL 的,大量的请求直接打到 MySQL,比如一般MySQL能抗2000条请求,现在每秒10000 条 SQL,可能就直接把 MySQL 给打死了,导致系统崩溃。但是高峰期一过就又没人了,QPS回到50,对整个系统几乎没有任何的压力。
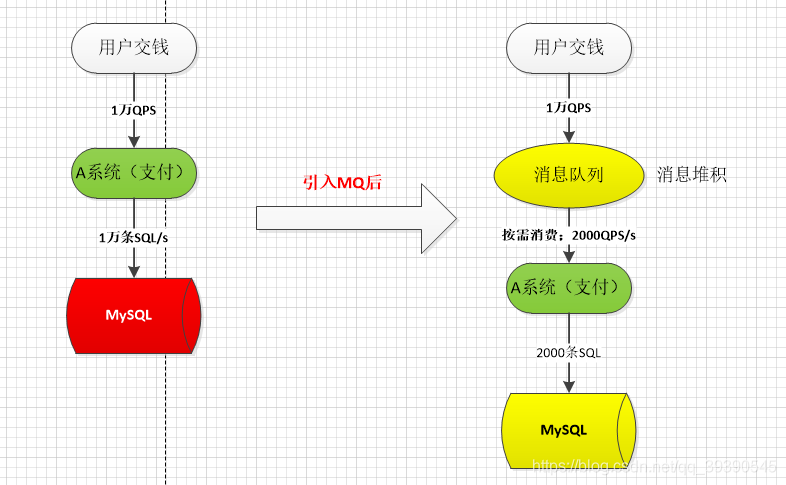
如果这里使用 MQ,每秒 1w 个请求写入 MQ,A 系统每秒钟最多处理 2000 个请求,因为 MySQL 每秒钟最多处理 2k 个。A 系统从 MQ 中慢慢拉取请求,每秒钟就拉取 2k 个请求,不要超过自己每秒能处理的最大请求数量就 ok了,这样下来,哪怕是高峰期的时候,A 系统也不会挂掉。当然了,用户的响应时间肯定会受影响,毕竟秒杀嘛,只要把前多少条请求处理好,其余的抢票失败就行了。
另外,MQ 每秒钟 1w 个请求进来,只处理 2k 个请求出去,结果会导致在中午高峰期,可能有几十万甚至几百万的请求积压在 MQ 中。
这个短暂的高峰期积压是 ok 的,因为高峰期过了之后,每秒钟就 50 个请求进 MQ,但是A 系统依然会按照每秒 2k 个请求的速度在处理。所以说,只要高峰期一过,A 系统就会快速将积压的消息给消费掉。
追问1:消息队列有什么优缺点
系统可用性降低
系统引入的外部依赖越多,越容易挂掉。本来你就是 A 系统调用 BCD 三个系统的接口就好了,人 ABCD 四个系统好好的,没啥问题,你偏加个 MQ 进来,万一 MQ 挂了咋整,MQ 一挂,整套系统崩溃的,你不就完了?如何保证消息队列的高可用?
系统复杂度提高
硬生生加个 MQ 进来,你怎么保证消息一定被消费?如何避免消息重复投递或重复消费?数据丢失怎么办?怎么保证消息传递的顺序性?
一致性问题
A 系统处理完了直接返回成功了,人都以为你这个请求就成功了;但是问题是,要是 BCD 三个系统那里,BD 两个系统写库成功了,结果 C 系统写库失败了,咋整?你这数据就不一致了。
面试题2:对于消息中间机,你们是怎么做技术选型的?
目前市面上比较主流的消息队列中间件主要有,Kafka、ActiveMQ、RabbitMQ、RocketMQ 等。
ActiveMQ和RabbitMQ这两由于吞吐量的原因,只有业务体量一般的公司在用,RabbitMQ由于是erlang语言开发的,我们都不了解,因此扩展和维护成本都很高,查个问题都头疼。
Kafka和RocketMQ一直在各自擅长的领域发光发亮,两者的吞吐量、可靠性、时效性等都很可观。
我们通过图表看看这几个消息中间机的对比:
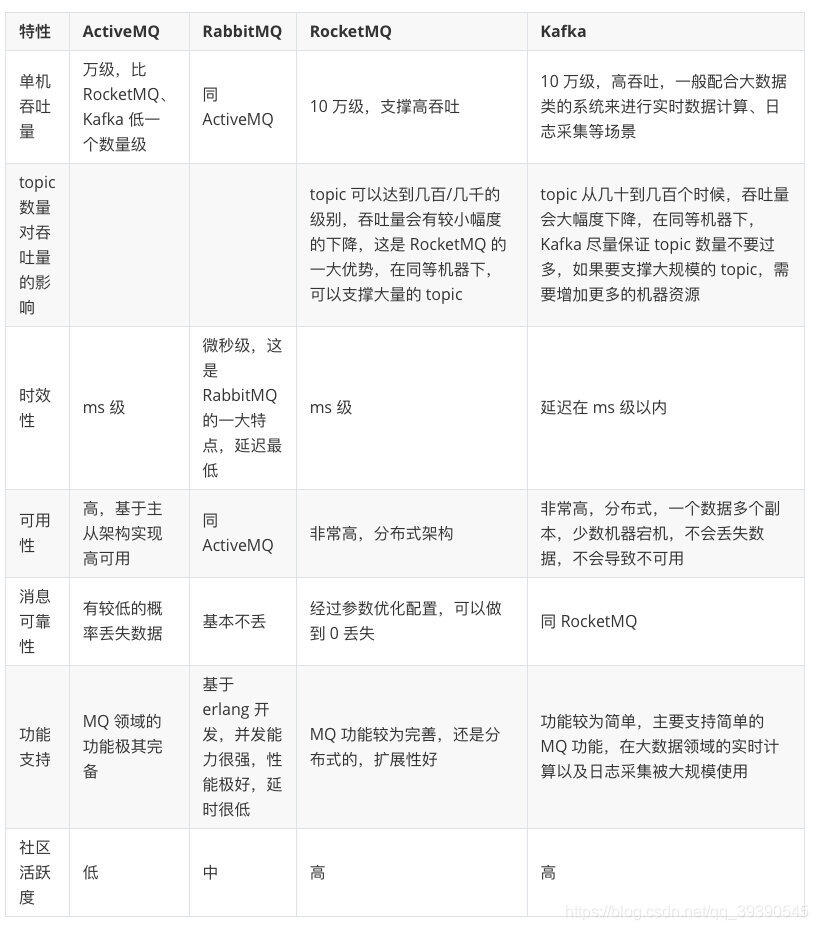
大家其实一下子就能看到差距了,就拿吞吐量来说,早期比较活跃的ActiveMQ 和RabbitMQ基本上不是后两者的对手了,在现在这样大数据的年代吞吐量是真的很重要。
面试题3:如何确保消息正确地发送至 RabbitMQ?如何确保消息接收方消费了消息?
发送方确认模式
将信道设置成confirm模式(发送方确认模式),则所有在信道上发布的消息都会被指派一个唯一的ID。
一旦消息被投递到目的队列后,或者消息被写入磁盘后(可持久化的消息),信道会发送一个确认给生产者(包含消息唯一ID)。
如果RabbitMQ发生内部错误从而导致消息丢失,会发送一条Nack(not acknowledged,未确认)消息。
发送方确认模式是异步的,生产者应用程序在等待确认的同时,可以继续发送消息。当确认消息到达生产者应用程序,生产者应用程序的回调方法就会被触发来处理确认消息。
接收方确认机制
消费者接收每一条消息后都必须进行确认(消息接收和消息确认是两个不同操作)。只有消费者确认了消息,RabbitMQ才能安全地把消息从队列中删除。
这里并没有用到超时机制,RabbitMQ仅通过Consumer的连接中断来确认是否需要重新发送消息。也就是说,只要连接不中断,RabbitMQ给了Consumer足够长的时间来处理消息。保证数据的最终一致性;
追问1:如何保证MQ消息的可靠传输?
以我们常用的RabbitMQ为例,消息不可靠的情况可能是消息丢失,劫持等原因;
丢失又分为:生产者丢失消息、消息队列丢失消息、消费者丢失消息;
生产者丢失消息:从生产者弄丢数据这个角度来看,RabbitMQ提供confirm模式来确保生产者不丢消息;
confirm模式用的居多:一旦channel进入confirm模式,所有在该信道上发布的消息都将会被指派一个唯一的ID(从1开始),一旦消息被投递到所有匹配的队列之后;RabbitMQ就会发送一个ACK给生产者(包含消息的唯一ID),这就使得生产者知道消息已经正确到达目的队列了;
如果rabbitMQ没能处理该消息,则会发送一个Nack消息给你,你可以进行重试操作。
消息队列丢数据:消息持久化。
处理消息队列丢数据的情况,一般是开启持久化磁盘的配置。
持久化配置和confirm机制配合使用,在消息持久化磁盘后,再给生产者发送一个Ack信号。
这样,如果消息持久化磁盘之前,rabbitMQ阵亡了,那么生产者收不到Ack信号,生产者会自动重发。
本文由 新·都在 原创,采用 CC BY-NC-SA 4.0 许可协议,转载请注明出处。



